목차
1. 제약 조건: UK, NOT NULL, CHECK
1-1 제약 조건 설정
1-2 제약 조건 설정 실습
2. 제약 조건 관리 - 추가 삭제와 비활성화
2-1 제약 조건 설정
2-2 제약 조건 설정 실습
3. 인덱스 구조와 이해
3-1 인덱스 (index)
3-2 인덱스 실습
1. 제약 조건: UK, NOT NULL, CHECK
1-1 제약 조건 설정
UK : 설정한 컬럼에 중복된 값이 들어가지 않도록 한다.
NOT NULL : NULL 값을 줄 수 없도록 한다.
CHECK : 행에 입력될 데이터의 조건을 설정한다.
● UK(Unique Key), NOT NULL 설정
CREATE TABLE 테이블(
.....
CONSTRAINT 제약조건이름 UNIQUE (컬럼));
CREATE TABLE 테이블(
컬럼 데이터_타입 CONSTRAINT 제약조건이름 NOT NULL,
......;
- UK는 고유 인덱스가 만들어진다.
- NOT NULL은 컬럼 레벨에서만 정의할 수 있다.
● CHECK 설정
CREATE TABLE 테이블(
.....
CONSTRAINT 제약_조건 CHECK (조건));
- 행에 입력될 데이터의 조건을 정의한다.
- 조건은 WHERE절에 기술하는 조건 형식과 동일하다.
- 본래 테이블 레벨에서 정의하나 현재는 컬럼 레벨에서도 정의가 가능하다.
- NOT NULL은 컬럼 레벨에서만 정의할 수 있으나, check 제약 조건을 이용해 테이블 레벨에서 정의가 가능하다.
: CHECK (컬럼 IS NOT NULL)
※ CHECK와 NOT NULL 제약 조건 내용 검색
SELECT constraint_name, search_condition FROM user_constraints
WHERE table_name = '테이블';
1-2 제약 조건 설정 실습
● UK, CHECK, NOT NULL을 적용한 테이블 생성
※ emp3 테이블
| 컬럼명 | eno(사번) | ename(이름) | gno(주민번호) | sex(성별) |
| PK/UK/NOTNULL | PK | NOT NULL | UK | |
| 참조테이블 | ||||
| 참조컬럼 | ||||
| CHECK | LENGTH(13) | (여, 남) | ||
| 데이터타입 | VARCHAR2 | VARCHAR2 | VARCHAR2 | VARCHAR2 |
| 길이 | 4 | 50 | 13 | 4 |
SQL> CREATE TABLE emp3 (
2 eno VARCHAR2(4),
3 ename VARCHAR2(50) CONSTRAINT emp3_ename_nu NOT NULL,
4 gno VARCHAR2(13),
5 sex VARCHAR2(2),
6 CONSTRAINT emp3_eno_pk PRIMARY KEY (eno),
7 CONSTRAINT emp3_gno_uk UNIQUE (gno),
8 CONSTRAINT emp3_gno_ch CHECK (LENGTH(gno)=13),
9 CONSTRAINT emp3_sex_ch CHECK (sex IN ('여','남')));
- gno(주민번호)와 같이 UK로 지정한 경우 해당 컬럼에 중복된 값이 입력되지 않도록 한다. NULL 값은 여러 개 입력 가능하다.
- UK로 지정한 컬럼을 부식별자 혹은 후보 식별자로 칭한다.
※ 추가된 제약 조건 확인
SQL> INSERT INTO emp3 (eno, ename, gno, sex)
2 VALUES ('1001', '문시현', '0602183123456','남');
SQL> INSERT INTO emp3 (eno, ename, gno, sex)
2 VALUES ('1002', NULL, '0605123123456','남');
// ORA‐01400 에러, ename null
SQL> INSERT INTO emp3 (eno, ename, gno, sex)
2 VALUES ('1003', '김민채', '0602183123456', '여');
// ORA‐00001 에러, gno 중복
SQL> INSERT INTO emp3 (eno, ename, gno, sex)
2 VALUES ('1004', '권아현', '060121312345', '여');
// ORA‐02290 에러, gno 길이
SQL> INSERT INTO emp3 (eno, ename, gno, sex)
2 VALUES ('1005', '권석현', '0601213123456', 'M');
// ORA‐02290 에러, sex 입력
다음과 같이 sql 파일의 인코딩 방식을 ANSI로 변경하면 테이블 명, 컬럼 명에 한글을 허용하여 파일을 읽어올 수 있다.

2. 제약 조건 관리 - 추가 삭제와 비활성화
2-1 제약 조건 설정
실제로는 테이블을 먼저 만들고 제약 조건은 alter table 문을 추가해 설정하는 것이 테이블 생성문에 제약 조건을 추가하는 것보다 가독성이 좋다.
● 제약 조건 추가 삭제
ALTER TABLE 테이블
ADD CONSTRAINT 제약조건이름 제약조건타입;
ALTER TABLE 테이블
MODIFY 컬럼 CONSTRAINT 제약조건이름 NOT NULL;
ALTER TABLE 테이블
DROP PRIMARY KEY | UNIQUE(컬럼) | CONSTRAINT 제약조건이름 [CASCADE];
// 여러 제약을 설정하는 경우
ALTER TABLE 테이블
ADD CONSTRAINT 제약조건이름 제약조건타입
ADD CONSTRAINT 제약조건이름 제약조건타입
ADD CONSTRAINT 제약조건이름 제약조건타입;
- NOT NULL을 제외하고 모두 ADD 명령으로 제약 조건을 추가한다.
- NOT NULL은 MODIFY 명령으로 추가한다.
그러나 'ADD ~ CHECK (컬럼 IS NOT NULL)' 로 추가하는 것을 권장한다.
- PK나 UK는 삭제 시에 참조 중인 FK를 먼저 삭제해야 한다.
CASCADE를 이용할 수 있다.
● 제약 조건 활성화 비활성화
ALTER TABLE 테이블
ENABLE CONSTRAINT 제약조건이름;
ALTER TABLE 테이블
DISABLE CONSTRAINT 제약조건이름 [CASCADE]
- PK와 UK가 ENABLE/DISABLE 될 때 인덱스도 생성/삭제된다.
- PK와 UK가 DISABLE 되려면 참조하는 FK가 지워지거나 비활성화되어야 한다.
CASCADE를 이용할 수 있다.
이때 인덱스를 non unique로 만들면 수정이 편해진다.
2-2 제약 조건 설정 실습
● 제약 조건 추가
※ class(강좌) 테이블
| 컬럼명 | cno(강좌번호) | cname(강좌명) |
| PK/UK/NOTNULL | PK | UK/NOT NULL |
| 참조테이블 | ||
| 참조컬럼 | ||
| CHECK | ||
| 데이터타입 | VARCHAR2 | VARCHAR2 |
| 길이 | 4 | 50 |
※ st(학생) 테이블
| 컬럼명 | sno(학생번호) | sname(이름) | cno(강좌번호) |
| PK/UK/NOTNULL | PK | ||
| 참조테이블 | class | ||
| 참조컬럼 | cno | ||
| CHECK | |||
| 데이터타입 | VARCHAR2 | VARCHAR2 | VARCHAR2 |
| 길이 | 4 | 50 | 4 |
SQL> CREATE TABLE class (
2 cno VARCHAR2(4),
3 cname VARCHAR2(50));
SQL> CREATE TABLE st (
2 sno VARCHAR2(4),
3 sname VARCHAR2(50),
4 cno VARCHAR2(4));
SQL> ALTER TABLE class
2 ADD CONSTRAINT class_cno_pk PRIMARY KEY (cno);
SQL> ALTER TABLE class
2 ADD CONSTRAINT class_cname_uk UNIQUE (cname);
SQL> ALTER TABLE class
2 MODIFY cname CONSTRAINT class_cname_nu NOT NULL;
SQL> ALTER TABLE st
2 ADD CONSTRAINT st_sno_pk PRIMARY KEY (sno);
SQL> ALTER TABLE st
2 ADD CONSTRAINT st_cno_fk FOREIGN KEY (cno) REFERENCES class (cno);
● 제약 조건 삭제
class와 st에 추가된 제약 조건을 모두 삭제한다.
SQL> ALTER TABLE st
2 DROP PRIMARY KEY;
SQL> ALTER TABLE st
2 DROP CONSTRAINT st_cno_fk;
SQL> ALTER TABLE class
2 DROP PRIMARY KEY;
SQL> ALTER TABLE class
2 DROP CONSTRAINT class_cname_uk;
SQL> ALTER TABLE class
2 DROP CONSTRAINT class_cname_nu;
- 삭제 순서에 유의한다.
- 다음 실습을 위해 제약 조건을 다시 추가한다.
● 제약 조건 비활성화
제약 조건의 상태를 확인하고 비활성화/활성화 한다.
SQL> SELECT table_name, constraint_name, status
2 FROM user_constraints
3 WHERE table_name IN ('CLASS','ST');
SQL> ALTER TABLE st
2 DISABLE CONSTRAINT st_sno_pk;
SQL> INSERT INTO st (sno, sname) values ('10','조조');
SQL> INSERT INTO st (sno, sname) values ('10','유비');
SQL> SELECT * FROM st;
3. 인덱스 구조와 이해
3-1 인덱스 (index)
인덱스란 특정 컬럼의 특정 값과 그 위치(rowID)를 매치시켜놓은 인덱스 테이블을 이용해 원하는 행을 검색하는 작업을 효율적으로 진행할 수 있도록 하는 것이다.
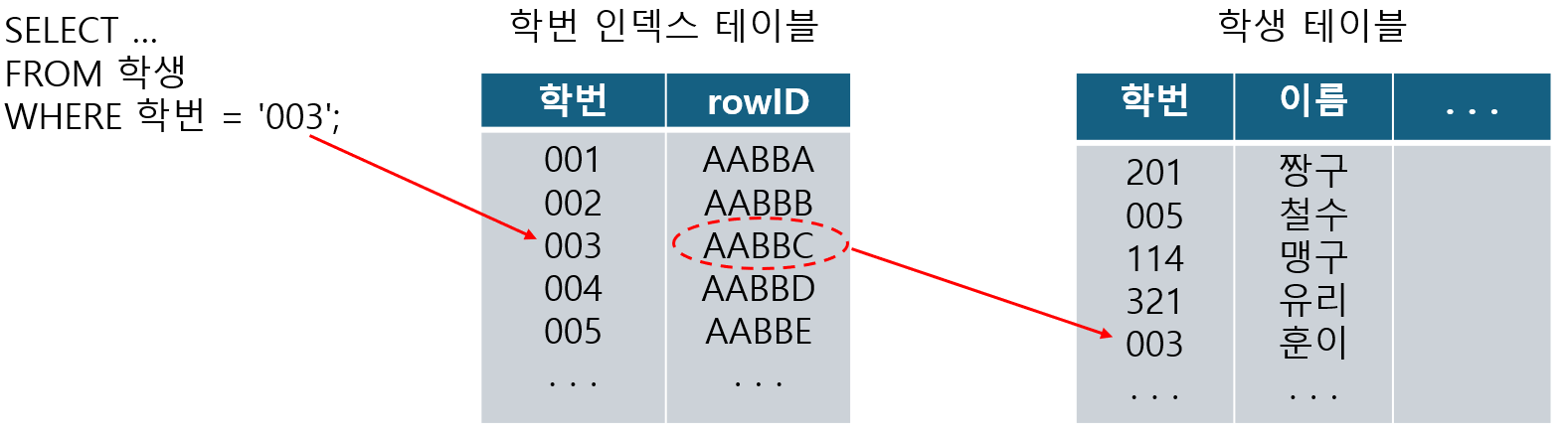
그러나 단순히 테이블의 행을 정렬해 출력하는 작업과 같이 검색을 원하는 행이 많을 경우 인덱스를 사용하는 것이 오히려 느릴 수 있으므로, 사람이 한번에 인지할 수 있는 범위 내에 있는 데이터를 읽을 경우 인덱스를 사용한다.
NULL 값은 rowID와 매치할 수 없어 인덱스를 이용할 수 없다.
● 인덱스의 종류
- 고유
고유 인덱스(Unique Index), 비 고유 인덱스(NonuniqueIndex)
고유 인덱스는 자동으로 생성되며 중복된 값을 허락하지 않는다.
비 고유 인덱스는 인덱스를 직접 생성했을 때 일반적으로 생성되며 중복된 값을 허락한다.
- 물리 구조
B-Tree Index, bitmap Index
● 인덱스의 생성
- 자동 생성
PK, UK로 지정된 컬럼은 자동으로 생성된다.
Unique Index가 생성된다.
- 수동 생성
CREATE INDEX 명령을 통해 직접 생성한다.
Non unique Index 가 생성된다.
FK 컬럼에 반드시 생성한다.
3-2 인덱스 실습
● 인덱스 생성과 삭제
CREATE INDEX 인덱스이름
ON 테이블(컬럼| 함수| 수식);
DROP INDEX 인덱스이름;
- 의미있는 인덱스 생성 조건
: 검색 데이터가 한 번에 확인이 가능한 정도일 경우
: where 절이나 조인에 사용되는 컬럼인 경우
: 데이터의 행이 매우 많은 경우
● 인덱스 확인
다음 문장을 이용해 인덱스를 확인할 수 있다.
SELECT c.index_name, c.column_name, c.column_position, i.uniqueness
FROM user_indexes I, user_ind_columns c
WHERE c.index_name = i.index_name;
SELECT index_name, column_expression
FROM user_ind_expressions;
- Column_position: 여러 컬럼으로 인덱스가 생성된 경우 컬럼의 순서
- Column_expressions:수식에 의해 만들어진 인덱스의 해당 수식
- PK(UK)에 의해 자동으로 생성된 인덱스의 이름은 PK(UK)와 동일하다.
- PK가 둘 이상의 컬럼으로 구성된 경우 컬럼의 순서는 매우 중요하다.
● 인덱스 생성 - FK
FK 컬럼에 인덱스를 추가한다.
SQL> CREATE INDEX course_pno_fk
2 ON course (pno);
SQL> CREATE INDEX score_cno_fk
2 ON score (cno);
SQL> SELECT i.table_name, i.index_name, c.column_name
2 FROM user_indexes i, user_ind_columns c
3 WHERE c.index_name = i.index_name
4 AND i.index_name LIKE '%FK'
5 ORDER BY c.table_name;
- FK는 인덱스가 자동으로 만들어지지 않는다.
- 기존PK 인덱스가 있는 컬럼은 새로 생성하지않는다.
● 인덱스 생성
STUDENT 테이블에 다양한 인덱스를 생성하고 조회한다.
SQL> CREATE INDEX student_sname_indx
2 ON student (sname);
SQL> CREATE INDEX student_major_sname_indx
2 ON student (major, sname);
SQL> CREATE INDEX student_coavr_indx
2 ON student (avr*4.5/4.0);
SQL> CREATE INDEX pr_ord_indx
2 ON professor (SUBSTR(orders,1,1));
- 여러 컬럼으로 인덱스가 만들어 질 때 구조는 해당 컬럼으로 정렬하는 경우와 동일하다.
- 인덱스는 컬럼 뿐 아니라 수식으로도 생성 가능하다.
● 인덱스 확인
STUDENT 테이블의 인덱스를 확인한다.
SQL> SELECT c.index_name, c.column_name, c.column_position
2 FROM user_indexes i, user_ind_columns c
3 WHERE c.index_name = i.index_name
4 AND c.table_name = 'STUDENT'
5 ORDER BY c.index_name, c.column_position;
SQL> SELECT index_name, column_expression
2 FROM user_ind_expressions
3 WHERE index_name = 'STUDENT_COAVR_INDX';
- 수식을 이용한 인덱스의 경우 COLIMN_NAME의 값이 일련번호로 검색된다.
- 수식은 USER_IND_EXPRESSIONS에서 검색한다.
● 인덱스 삭제
SQL> DROP INDEX student_major_sname_indx;
SQL> DROP INDEX student_sno_pk;
// ORA‐02429 에러발생
'일일 정리' 카테고리의 다른 글
| 뷰 (View), 시퀀스 (Sequence), 모델링 (0) | 2025.03.20 |
|---|---|
| [Semi-Project] 기업 네트워크 환경 구축 (0) | 2025.03.19 |
| 테이블 생성과 데이터 타입(DDL), 테이블 관리, 제약 조건 : PK, FK (0) | 2025.03.18 |
| Samba (1) | 2025.03.10 |
| PHP - DB 접속 (0) | 2025.03.09 |